
1. Reflexionem sobre la tecnologia, la informació i el coneixement en un món de dades
1.0 Què faràs amb aquests continguts?
Treballes a l’administració en un entorn totalment assistit per ordinador. Davant dels ulls hi tens una pantalla de l'ordinador del lloc de treball. A la butxaca, segurament, hi tens un mòbil que tant pot ser particular com de feina. Fins i tot pot ser que en tinguis dos. A casa teva, és possible que tinguis unes quantes pantalles més: la del televisor, la de la tauleta, les d'altres ordinadors personals, etc.
En aquest mar de pantalles i símbols hi veus de tot: sòrdids documents administratius que són el teu pa de cada dia, però també multitud d’informacions i dades que, ordenadament o desordenadament, hi tenen relació. I a casa, és clar, també veus i escoltes, contínuament, tota mena de continguts digitals.
Avui t’ha sorprès una piulada que parla de l’atenció al públic en el servei on treballes. Sembla que un usuari s’ha enfadat. Un munt de persones l’han repiulada i ara t’arriba que un diari digital n’ha fet una notícia.
El teu cap et demana informació sobre tot el que s’ha publicat i sobre el que hi ha al darrere. Com ho fas? Evidentment, el mateix canal pel qual ha arribat la primera informació, Internet, t’hauria de servir per portar a terme aquesta tasca.
Obres X (abans Twitter) i hi veus de tot: vídeos de gatets, ocurrències, diatribes polítiques i informació sobre el cas que t’ocupa. Però, te’n pots refiar? Et sents com si estiguessis a la selva: lletres, números, vídeos, imatges… Algunes són reals, però d’altres són falses. Saps, a més, que la intel·ligència artificial facilita la creació d'informacions falses amb aparença real en formats ben diversos (textos, àudios, vídeos, imatges). A més, com a empleat públic, sents la necessitat de prestigiar l’entorn professional que aquesta notícia, com tantes altres, contribueix a embrutar.
Necessites una guia per no perdre’t ni sucumbir en aquest safari de símbols i signes on la veritat i la falsedat es tornen tan precàries.
A la segona unitat, et facilitarem instruccions pràctiques per fer cerques amb els cercadors convencionals que hi ha a Internet, és a dir, Google, Bing, DuckDuckGo, etc., i d'altres d'ús més específic amb tècniques avançades.
A la tercera, t'introduirem a les intel·ligències artificials generatives com a eines per cercar i formatar informació.
A la quarta, obtindràs informació sobre el canvi continu que hi ha a Internet i instruments per gestionar-lo i tenir sempre actualitzades les cerques que has après a fer a la primera part.
A la cinquena unitat, t'explicarem la confusió entre veracitat i falsedat que protagonitza la Internet dels nostres dies i et donarem instruments per defensar-te'n.
Si segueixes el curs, evidentment no esdevindràs un documentalista ni un expert en elaboració de dossiers de premsa ni tampoc un professional de la verificació d'informacions periodístiques, però sí que hauràs fet unes reflexions que et faran veure Internet d'una altra manera i disposaràs d'eines i coneixements que t'ajudaran a filar prim quan t'encaris amb una pantalla amb informació.
1.1 Neutralitat i tecnologia
Agrada
l'electrònica agrada i electritza prô
prô els programes emprenyen,
empenyen a paranys, t'apamen
i per poc que et despistis t'empresonen.
Enric Casasses, T'hi sé (2013)
Abans de començar a endinsar-nos en el món de la informació, cal que et posis en guàrdia. La percepció que tens de la realitat està mediada per molts elements. Els primers, òbviament, són els sentits. Si ets daltònic, per exemple, tindràs una percepció dels colors totalment diferent de les persones que no en són. Si ets miop, saps que tindràs dificultats (que amb l’edat potser es tornaran avantatges) en determinades percepcions.
Però els humans no en tenim prou amb els sentits. Entre la realitat i nosaltres hi posem altres elements intermedis. Un dels més evidents és el simbolisme en general. Nosaltres podem considerar que una pedra és una pedra, però segons com la trobem en un camí potser interpretarem que l’han posada per orientar-nos geogràficament. Si a més alguna cosa ens fa creure que tocant-la tindré sort, la pedra encara agafarà més significats. Per tant, la nostra percepció de la realitat és mediada, per començar per nosaltres mateixos.
. Una pedra pot ser només una pedra o tenir moltes altres funcions.")
Ara bé, la principal mediació que interposem entre nosaltres i la realitat és el llenguatge. El llenguatge ho canvia tot. Disposar d’un llenguatge ric i precís ens dotarà d’una percepció més rica i precisa de la realitat. Percebre la realitat d’un cos amb un domini del llenguatge d’un metge ens dirà unes coses i percebre-la amb la sensibilitat simbòlica del llenguatge poètic ens en dirà unes altres. Evidentment, percebre la realitat del cos amb un llenguatge religiós o eròtic també ens en dirà unes altres de diferents. Quines són més reals? És impossible de dir perquè la nostra percepció d’aquell cos, ja romandrà per sempre més modificada. El fet de parlar una llengua o un altre també pot introduir matisos de percepció, si bé en llengües properes a penes tenen importància.
Ludwig Wittgenstein (1889-1951)
Però n’hi posem moltes altres de capes entre nosaltres i la realitat i una de molt important és la tecnològica. Les tecnologies comparteixen elements materials amb elements simbòlics i sovint es mesclen amb el llenguatge. En tenim una prova ben senzilla amb els instruments de mesura del temps. No tindrem la mateixa percepció de la realitat si ens guiem per un rellotge de sol en una masia, que veiem de tant en tant, que si ens movem en un entorn urbà burocràtic o industrial amb un rellotge de polsera que ens marca tirànicament les hores de les reunions o amb un mòbil a la butxaca on el temps ens arriba en forma d’avisos mentre es dissol en l’scroll infinit de les xarxes socials.

La percepció de la realitat mediada per la tecnologia (des d’unes simples ulleres a un ordinador) ens ha de posar en guàrdia. Els ordinadors, els telèfons intel·ligents i les xarxes socials no només ens connecten amb altres persones i fonts d’informació, sinó que també fan d’intermediaris.
És neutral aquesta mediació? Hi ha tres mirades filosòfiques i totes tres ens ajuden a posar-nos en guàrdia i ser ben conscients que aquesta mediació existeix.
Primera mirada: la tecnologia és neutra, però nosaltres no en som
Karl Jaspers, un filòsof actiu principalment durant la primera meitat del segle XX, presenta una visió neutral de la tecnologia. La tecnologia no és un fi per ella mateixa, sinó un instrument per assolir un fi. Per tant, hem de tenir molt clar quin objectiu tenim quan utilitzem la tecnologia ja que la finalitat és el que marcarà com ens condiciona la tecnologia mateix que, segons afirma també Jaspers, ha de ser guiada per la raó. La lliçó de Jaspers és doncs que hem de ser conscients del que fem i hem de mantenir les regnes de la raó i l’enteniment. Això, tan senzill, hauríem de tenir-ho present quan fem intro per obtenir una cerca de Google i amb més motiu quan interactuem amb una intel·ligència artificial generativa.
Karl Jaspers
Segona mirada: la tecnologia no és neutra, sinó que ens determina
Martin Heidegger, també durant la primera meitat del segle XX, sostenia que la tecnologia no és només una eina, sinó una forma de revelar la realitat, l’ésser. Quan interactuem amb la realitat amb una mediació tecnològica accedim a la realitat totalment condicionats per aquesta mediació perquè la realitat se’ns revela precisament mitjançant la tecnologia. La mirada de Heidegger va tenir continuïtat en la de Marshall Mc Luhan. El seu diagnòstic de l’era de la televisió i la ràdio són perfectament útils en el món digital: la tecnologia és una extensió del nostre cos i condiciona la nostra percepció.
Per tant, el mitjà és el missatge i fins i tot és el massatge, ja que el mitjà que utilitzem per accedir a la realitat ens va fent un massatge que modifica la nostra musculatura perceptiva i emocional.
La caiguda de les Torres Bessones és indestriable per a nosaltres de la imatge televisiva i la televisió amb aquella successió inacabable de plans d’avions estavellant-se (sempre els mateixos avions, però vistos des de llocs diferents) va modelar com qui va fent massatges la nostra percepció de la por i X (abans Twitter) ha modelat el grau de tensió amb què la gent discuteix portant-lo al paroxisme.
Martin Heidegger. Die Frage nach der Technik (1949)
Marshall Mc Luhan. Understandign media: the extensions of man (1964)
Marshall Mc Luhan. The medium is the massage: an inventory of effects (1967)
Tercera mirada: la trobada entre persones i tecnologies reconfigura les relacions
Finalment, la teoria de la mediació de Bruno Latour sosté que les tecnologies no només connecten les persones amb el seu entorn, sinó que reconfiguren activament tant la relació amb l'entorn com la relació entre les persones i les tecnologies mateixes. És a dir, quan una eina es fa servir, no es limita a executar el "programa d'acció" previst pels seus creadors, sinó que la seva utilització real per part d'algú, transforma tant la funcionalitat de l'eina com les dinàmiques i les relacions entre els implicats.
Un mòbil, per exemple, potser va ser pensat per trucar algú i es va enriquir amb els missatges i una càmera. Al final, a causa de l'ús que n'han fet lliurement els usuaris, aquestes dues funcions són les que han acabat dominant fins al punt de transformar la relació amb el mòbil mateix, però també la relació entre les persones (no és igual un sopar d'amics sense mòbils que un sopar on tothom té el mòbil a la mà: la gent hi és, però alhora és en un altre lloc).
Bruno Latour. Pandora's Hope: An Essay on the Reality of Science Studies (1999)
Ja ho veus, doncs, si vols accedir a la "realitat" has de saber que buscar a Google no és un gest innocent que te la reveli de manera "neutra". Al contrari, si accedeixes a Google ho faràs condicionat pels teus propis objectius i context i Google mediatitzarà el teu accés a la realitat sobre la qual et vols informar perquè haurà passat pel seu sedàs i la seva tria. T'haurà, doncs, determinat. I a més, modificarà la teva relació amb els altres i amb l'eina mateix.
1.2 El bosc s’ha tornat una selva
que deixen anar, de vegades, paraules confuses;
l’home hi camina per un bosc de símbols
que l’observen amb una mirada familiar."
Charles Baudelaire. Les flors del mal. Trad. Jordi Llovet. Ed. 62. 2007
És una quarteta del sonet “Correspondències” de Charles Baudelaire. En un primer moment, Internet era efectivament un bosc de signes plaent. Ara ja no és cap bosc. És una selva i de grat o per força t’hi trobes dintre. Com totes les selves és plena de llocs paradisíacs, però també perills i paranys.
Anys enrere, un curs dedicat al web social i orientat a empleats públics tenia com a introducció un relat optimista sobre les possibilitats d'Internet i molt especialment del web 2.0. En aquell moment, la possibilitat que tothom pogués publicar fàcilment els seus plantejaments i opinions i compartir-los amb tota la societat es veia com una contribució a fer un món millor. L'èxit d'eines tan útils com la Viquipèdia ho feien preveure així. Però en pocs anys les coses han canviat molt.
El que anys enrere, als primers 2000, era una obertura marcada per l’aparició dels blogs i, més tardanament, de Facebook, ha canviat justament amb el triomf de les xarxes socials. Buscar-hi informació ha esdevingut complex tant per la gran quantitat i diversitat de dades que hi trobem com pel fet que canvien contínuament. Relacionar-nos-hi, a més, té implicacions en matèria d’identitat i protecció de dades personals i també psicològiques i conductuals, fins al punt que podem arribar a tenir dificultats per mantenir l'atenció. Per postres, costa distingir allò que és cert d'allò que és fals, problema que s'ha accentuat amb la socialització de les intel·ligències artificials generatives, popularitzades mitjançant xatbots (del tipus ChatGPT). Tot i això, ens en podem sortir perfectament si hi reflexionem i adoptem certes tècniques i actituds. Això és el que mirarem de fer a continuació.
Byung-Chul Han. La sociedad de la transparencia. Herder. 2013
La millor actitud i les millors eines
Per a un empleat públic que vol treballar amb rigor, la qualitat de la informació és un requisit indispensable. Però els que aporten informació a Internet sovint es troben darrere de màscares. Cada vegada costa més de saber si allò que llegim és veritat o és, ras i curt, una enredada, i el problema no se cenyeix només a les xarxes socials. En més d'una ocasió afecta mitjans que, en altre temps, havien estat ben prestigiosos. Alguns d'aquests han caigut en el parany de les imatges o els textos falsos generats mitjançant intel·ligències artificials o altres sistemes.
D'altra banda, la cerca d'informació pot semblar la cerca d'una agulla en un paller. Hi ha molta informació disponible perquè cada vegada hi ha més veus que en generen atretes pels avantatges en relacions socials o expressió personal d'eines com els blogs, les xarxes, etc.
Com explica Jaron Lanier en un llibre que us recomanem (Contra el rebaño digital. Debate. 2011), darrere d'aquests productes que provoquen la creació de tants i tants continguts s'hi amaga la necessitat de fer rendibles el que ell denomina "servidors sirena", ordinadors de gran capacitat que necessiten grans recursos per al seu funcionament. Els gestors d'aquestes infraestructures ofereixen grans gratificacions perquè la gent comparteixi contingut a la xarxa (i no tan sols en l'àmbit expressiu, també comercialment: Ebay, Amazon, etc.). Aquest contingut, que transformat en dades, és una eina de màrqueting de primer ordre, també és la clau del seu negoci i ha comportat la transformació de molts aspectes de la nostra societat, amb clares implicacions sociològiques. També respon a aquesta lògica la primera onada de xatbots basats en intel·ligència artificial popularitzats de manera molt ràpida l'any 2022.
Si tothom esdevé proveïdor d'informació, els volums esdevenen inabastables. A efectes de negoci, que part d'aquesta informació pugui ser irrellevant o de baixa qualitat, no és problemàtic. Sí que ho és quan, per la nostra tasca professional diària, ens veiem en la necessitat de relacionar-nos-hi. Ens calen instruments teòrics i pràctics per cercar aquesta informació amb precisió, per seguir-la (ja que està subjecta a canvis) i també per escatir-ne la precisió i la veracitat. En aquest sentit, cal advertir de l'ambivalència que en aquesta tasca poden tenir les eines d'intel·ligència artificials (que només es poden fer servir en l'àmbit professional si hi ha orientacions corporatives i respectant-les escrupolosament i en cap cas introduint-hi informació organitzacional).
Tingues present també que "les eines són eines i el programari és programari". Aquí t'explicarem a fer servir determinades eines, determinats programes, però ben segur que sortiran programes millors que els substituiran. Convé doncs que t'habituïs a entendre'n sobretot la utilitat i les prestacions amb una òptica d'intercanviabilitat. No dubtis a canviar de programes si en trobes de millors. Tot el que hagis après aquí et servirà, en essència, per a tots.
Una selva amb perills, sobretot emocionals
Tot i l’estratègia que les institucions públiques han portat a terme a les xarxes socials, com a empleats públics hem de ser conscients que en aquestes xarxes hi ha moments de gran hostilitat i enfrontament que, en determinades ocasions, pot impactar sobre les organitzacions en què treballem.
Christian Rudder. Dataclismo. Aguilar. 2016
Si hem de buscar informació en aquest entorn hostil, ben segur que serà una operació que, com a empleats públics, ens pot suposar una erosió emocional i cal que ens cuirassem i sapiguem separar adequadament les emocions, que és el terreny psicològic en què sovint es vehiculen les crisis a les xarxes socials, de la tasca racional de trobar un desllorigador tècnic als problemes que es plantegen. Això no sempre és fàcil.

Alguna vegada el teu servei públic ha estat objecte de crítica o polèmica a les xarxes socials o a la premsa? Com ho has viscut?
1.3 Abundància d’informació, importància de les dades
En el moment d’elaborar la primera versió d'aquest curs la quantitat i diversitat d’informació i dades que hi ha a Internet impressiona. Segons Internet Live Stats, hi ha:
- 1.710.635.383 webs accessibles a la xarxa
- 2.299.670.036 perfils de persones a Facebook
I en les primeres hores del dia en què s’ha elaborat aquest text:
- S’han enviat 143.921.698.650 missatges de correu electrònic
- S’han fet 3.755.075.796 de cerques a Google
- S’han actualitzat 3.574.976 de blogs
- S’han fet 421.872.631 piulades a X (abans Twitter)
- S’han visualitzat 3.924.300.384 vídeos a Youtube
- S’han publicat 45.774.867 fotos a Instagram
- Han circulat 3.817.840.333 gigabites d'informació
Es calcula que tota la informació continguda a Internet i els ordinadors que en formen part és de 9 zetabytes de dades. Per fer-vos-en una idea:
- 9 zetabytes = 9.000 exabytes
- 9 exabytes = 9.000 petabytes
- 9 petabytes = 9.000 therabytes
- 9 therabytes = 9.000 gigabytes
- 9 gigabytes = 9.000 megabytes
- 9 megabytes = 9.000 kilobytes
- 9 kilobytes = 9.000 bytes
Per tant, 9 zetabytes serien 9 x 10 elevat a 21 bytes. Per entendre què suposa, et proposem un exemple expressat en temps i un exemple expressat en espai:


Michiko Katukani. La muerte de la verdad. Rústica Ensayo. 2019
Com canvia el volum d'informació disponible en una casa quan hi entra una pantalla connectada a Internet? Imagina't un pagès en una masia abans d'Internet i compara-ho amb la teva situació actual.
Dades, informació, coneixement, saviesa
Marina Garcés. Nova il·lustració radical. Anagrama. 2017
Internet conté doncs una quantitat ingent de dades i, també, d’informació i coneixement. Aquests tres conceptes normalment es representen en forma de piràmide, l’anomenada "Piràmide de la jerarquia del coneixement", que és la següent:

Fixem-nos en les franges d'aquesta piràmide:
- Capa base (dades): Les dades són unitats bàsiques d'informació, que poden ser estructurades (una base de dades) o no estructurades (un fitxer de text amb una llista, per exemple).
- Segon nivell (informació): La informació són dades organitzades i processades per a ser enteses. La manera com s'organitzen ja té una intencionalitat.
- Tercer nivell (coneixement): El coneixement és l'assimilació i la integració personal o col·lectiva de la informació, fet que en suposa una transformació i adaptació.
- Pic de la piràmide (saviesa): La saviesa és la consciència del mateix coneixement que dona plenes capacitats per adoptar decisions, ja que si tenim saviesa sabem els límits d'allò que coneixem.
Un exemple per a empleats públics:
- La llista caòtica de totes les atencions al públic d’una oficina fetes d'anotacions en fulls de paper, assentaments en ordinadors i llistes de sol·licituds presentades serien dades.
- Una relació ordenada i classificada de totes les atencions al públic que s'han fet, tractades estadísticament i presentades de manera entenedora, serien informació.
- Un informe sobre l'evolució de l'atenció al públic amb una valoració de les tipologies d'usuaris i les implicacions socials i institucionals que comporta seria coneixement.
- Saviesa la demostrarien aquells gestors que convertissin aquest coneixement en grans millores en l’atenció que es dona als ciutadans.
Alguns autors han presentat aquest triangle a la inversa. Representaria la situació pròpia d’una societat amb un baix accés al coneixement, per exemple la societat europea del segle XIX i la primera meitat del XX. La piràmide anterior s’uniria a aquesta per sobre formant un rombe. Llegiu-la de baix cap a dalt:


Actualment, ens trobem que la satuació de dades i informativa ens pot portar al punt zero, és a dir la ignorància, però per excés de dades i d’informació:

Marina Garcés. Nova il·lustració radical. Anagrama. 2017
Tot plegat ens porta a una conclusió que expressa molt bé el pedagog australià Neil Fleming i que té molta relació amb el que intentarem fer aquest curs:
Flemming, N. Coping with a Revolution: Will the Internet change learning. 2006
Aquesta darrera afirmació s'accentua amb la popularització de la intel·ligència artificial i singularment de les intel·ligències artificials generatives, amb serveis populars com ChatGPT. Si fins ara les màquines, autònomament, eren capaces de generar dades i fins i tot oferir-les estructurades com a informació, ara mateix ja generen textos amb pretensió de ser coneixement.
L’objectiu d’aquests continguts no és que us convertiu en mers recopiladors de dades, ni tan sols en mers recopiladors d’informació. Tampoc, a l’altre extrem, que esdevingueu savis o els únics coneixedors de la veritat. L’objectiu és que sigueu capaços de trobar informació amb precisió perquè la vostra organització la pugui convertir en coneixement i que tingueu recursos per afrontar tant l’excés d’informació com les confusions entorn de la certesa i la falsedat que l’acompanyen.
Quan siguis al lloc de treball, mira al voltant teu: papers, pantalles, etc. Què hi tens? Dades, informació, coneixement…?
Dades obertes
Dades obertes són dades que s’ofereixen sense restriccions, per ser utilitzades en qualsevol àmbit. Qualsevol usuari pot utilitzar-les, modificar-les combinar-les i compartir-les fins i tot per a usos comercials. Són d’ús lliure i generalment, també, d’accés lliure, tot i que poden tenir costos. A efectes d’aquest curs són un tipus de dades que ens poden ser molt útils en la recerca d’informació, tant aquelles que ofereixen grans empreses com X (abans Twitter) (mitjançant la seva API) com les que ofereixen les administracions. D'aquestes, més endavant t'explicarem com fer-hi cerques.
Dades massives o “big data”
Les dades massives o "big data" són conjunts de dades que se solen caracteritzar per la seva voluminositat, per la velocitat a l’hora d’accedir-hi i per la varietat (les anomenades tres “v” del big data). No se solen fer servir per trobar-hi informació de detall, cosa que en determinades circumstàncies es pot fer, sinó perquè amb programes d’intel·ligència artificial permeten descobrir correlacions entre les mateixes dades que poden resoldre un determinat problema. L’exemple clàssic és quan l’observació de les cerques sobre medicaments per a la grip a Google permetia dibuixar, perfectament, el mapa de l’expansió d’aquesta epidèmia anual als EUA.
Mayer-Schömberger & Cukier. La revolución de los datos masivos. Turner Nogma. 2013
La intel·ligència artificial que opera amb les dades massives no és la denominada simbòlica, que es basa en l’aprenentatge d’algunes regles per imitar el comportament humà, sinó la que aprèn directament de les dades, buscant-hi regularitats mitjançant algoritmes de mineria de dades, descobrint i aprenent directament les regles que les regulen (aprenentatge automàtic o “machine learning”) o contrastant i ponderant diverses anàlisis seguint el model de les connexions neuronals (aprenentatge profund o “deep learning”).

A efectes d’aquest curs, les dades massives combinades amb la intel·ligència artificial t'interessen perquè són part principal de la complexitat que ha anat imperant a Internet i que et fa difícil d’accedir a la informació que et convé: sovint, quan cerques alguna cosa, la intel·ligència artificial ja sap qui ets, gràcies a l'anàlisi d'aquestes dades massives, i canvia allò que les pantalles t'ensenyen. Ho trobaràs explicat a l'apartat sobre la "bombolla de filtres", en aquesta mateixa unitat.
Christian Rudder. Dataclismo. Aguilar. 2016
Pedro Domingos, The master algorithm. Penguin. 2017
Les dades massives ja són presents a la teva vida amb tota seguretat. Fixa't en els llocs on vas durant el dia, el que dius o el que cerques a Internet. L'endemà, fixa't en el fet que t'ofereixen els anuncis que veus a la xarxa. Hi ha relació?
1.4 Intel·ligència artificial, dades i informació
La intel·ligència artificial no és una novetat en el món de les dades. Als anys 70 i 80 del segle XX, la combinació de dades amb ordinadors (anomenats "ordinadors" o "computadores" precisament perquè servien per tractar dades, és a dir, ordenar-les o comp[u]tar-les) va obrir unes perspectives inèdites. Va ser l'època d'aparició de les bases de dades relacionals, estructurades en camps i registres, i dels primers llenguatges de programació netament orientats a dades (com SQL, pensat per abordar les bases de dades relacionals).
Als anys 90, la tecnificació de les dades es va incrementar amb sensibles millores de programari i maquinari, l'aparició de grans magatzems de dades (data warehousing) i les primeres eines estadístiques i models predictius amb programaris com SAS, SPSS i R, actualment en boga però nascut el 1993.
A partir dels 2000, amb la generalització d'Internet, les dades van créixer espectacularment i van sorgir eines per processar-les massivament, per exemple Google Map Reduce (després, Hadoop). N'hi ha tantes, de dades, que les metàfores canvien i es parla de mineria de dades (data mining) com si parléssim de cerca de filons d'or enmig de tones de pedra o carbó.
És però a partir de 2010 quan es generalitzen tècniques ja existents com aprenentatge automàtic (machine learning) i aprenentatge profund (deep learning) que s'inscriuen ja en el paradigma del que avui entenem com a intel·ligència artificial i que permeten anàlisi en temps real a més de generar noves figures professionals com els científics de dades.
De 2020 ençà, el naixement dels grans models preentrenats de dades com GPT l'anàlisi de dades i la intel·ligència artificial han quedat totalment vinculades i sovint l'accés a les dades es fa ja mitjançant eines d'IA. Això genera inquietuds en aspectes com la privadesa, la propietat intel·lectual de les dades, els biaixos que puguin tenir, la governança que exigeixen o l'explicabilitat de les accions que s'hi porten a terme. De tot això, en parlarem a l'apartat 3 del curs.
| Any | Eina | Millora | Organitzacions i persones |
|---|---|---|---|
| 1970 | Bases de dades relacionals | Gestió eficient de dades estructurades | Edgar F. Codd (IBM) |
| 1970s | SQL | Llenguatge per gestionar bases de dades relacionals | IBM |
| 1976 | SAS | Eines per a l'anàlisi estadística | SAS Institute |
| 1980 | SPSS | Programari per a l'anàlisi estadística | SPSS Inc. (ara IBM) |
| 1993 | R | Llenguatge i entorn per a càlcul estadístic | Ross Ihaka i Robert Gentleman |
| 2004 | MapReduce | Processament distribuït de grans dades | |
| 2005 | Hadoop | Entorn de treball per processar grans volums de dades (Big Data) | Apache Software Foundation |
| 2015 | TensorFlow | Biblioteca per al desenvolupament de models d'aprenentatge automàtic (Machine Learning) | |
| 2016 | PyTorch | Biblioteca per a aprenentatge profund (deep learning) i IA | Facebook (Meta) |
| 2020 | GPT (Generative Pre-trained Transformer) | Models preentrenats | OpenAI |
(vegeu a la unitat següent més informació sobre l'evolució de la IA)
1.5 Del web centrífug al web centrípet
La recuperació d'informació mitjançant els xatbots d'IA i la manera com aquestes eines processen la informació provoca que, a la pràctica, naveguem menys i consultem menys pàgines. Fa temps que existeix el concepte de web centrífug i web centrípet, que va encunyar el professor Carlos A. Scolari al seu excel·lent blog Hipermediaciones. Google era tradicionalment l'exemple de web centrífug perquè hi anàvem a buscar informació i des d'allí saltàvem a les pàgines que contenien la informació original. Ens centrifugava cap a aquestes pàgines que, en rebre trànsit, en sortien beneficiades. En canvi, Facebook era centrípet perquè els continguts d'altres pàgines hi apareixien incrustats i sovint reproduïts a nivell, sobretot, dels primers titulars i paràgrafs: ens allunyava, de fet, de les altres pàgines.
En un escrit de 2024, el mateix professor explica que Google, ara mateix, ja integra a la primera cerca molts continguts preprocessats obtinguts d'altres pàgines i ja ha esdevingut més centrípet. Ho veureu molt clarament si busqueu la paraula pluja:
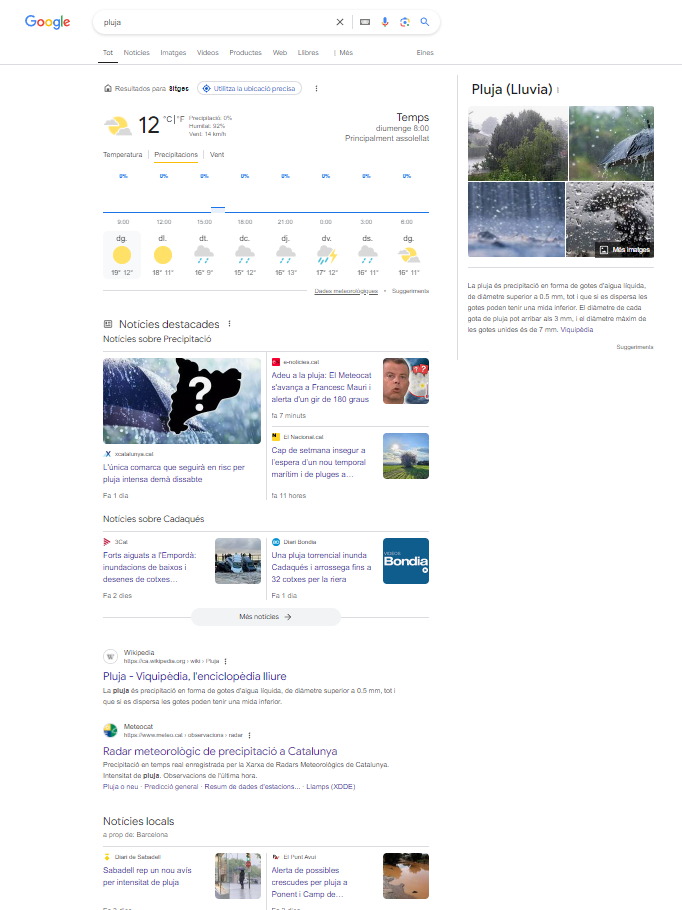 Com podeu comprovar, us ofereix informació meteorològica, fotografies, text extret de wikipèdia, una tria de notícies que permet fer-se'n perfectament a la idea del que diuen i els resultats convencionals apareixen secundàriament més avall. Tot això és possible gràcies a la intel·ligència artificial. Ara bé, en el moment que la informació la busquem directament mitjançant els xatbots d'IA, el caràcter centrípet serà absolut ja que, en alguns casos, no tindrem ni la referència de la pàgina on la informació s'ha obtingut. Això tindrà un impacte clar sobre tot l'ecosistema web, ja que el nombre de visites a moltes pàgines baixarà en picat i tots ens deixarem mediatitzar encara més a l'hora d'obtenir informació.
Com podeu comprovar, us ofereix informació meteorològica, fotografies, text extret de wikipèdia, una tria de notícies que permet fer-se'n perfectament a la idea del que diuen i els resultats convencionals apareixen secundàriament més avall. Tot això és possible gràcies a la intel·ligència artificial. Ara bé, en el moment que la informació la busquem directament mitjançant els xatbots d'IA, el caràcter centrípet serà absolut ja que, en alguns casos, no tindrem ni la referència de la pàgina on la informació s'ha obtingut. Això tindrà un impacte clar sobre tot l'ecosistema web, ja que el nombre de visites a moltes pàgines baixarà en picat i tots ens deixarem mediatitzar encara més a l'hora d'obtenir informació.
Carlos A. Scolari. Hipermediaciones
